NoSQL 原理概述
pika 设计
pika 在设计的时候支持了两种运行模式,即经典模式和分布式模式。
| 模式 | 原理 |
|---|---|
| 经典模式 | 即一主多从模式,安装 pika 实例维度,即 1 个 pika 实例的数据可以被多个从实例数据同步。 |
| 分布式模式 | 即用户的数据集合称为 table,将 table 切分成多个分片,每个分片称为 slot,对于某个 key 的数据是由哈希算法计算来决定属于哪个 slot,将所有 slots 及其副本按照一定策略分散到所有的 pika 实例中,每个 pika 实例有一部分的主 slot 和一部分从 slot,主从的维度为 slot。 |
官网原理图如下
经典模式
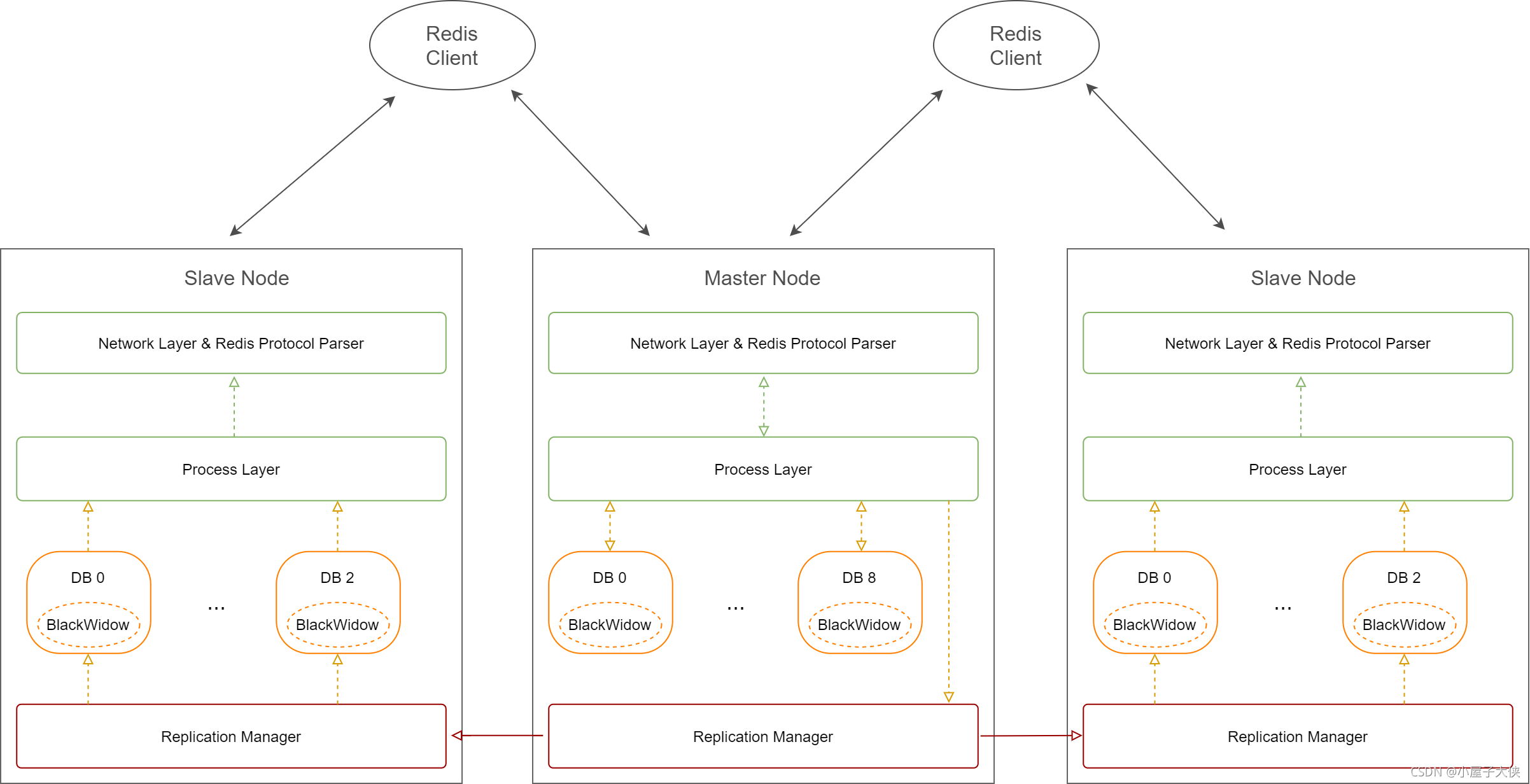
分布式模式
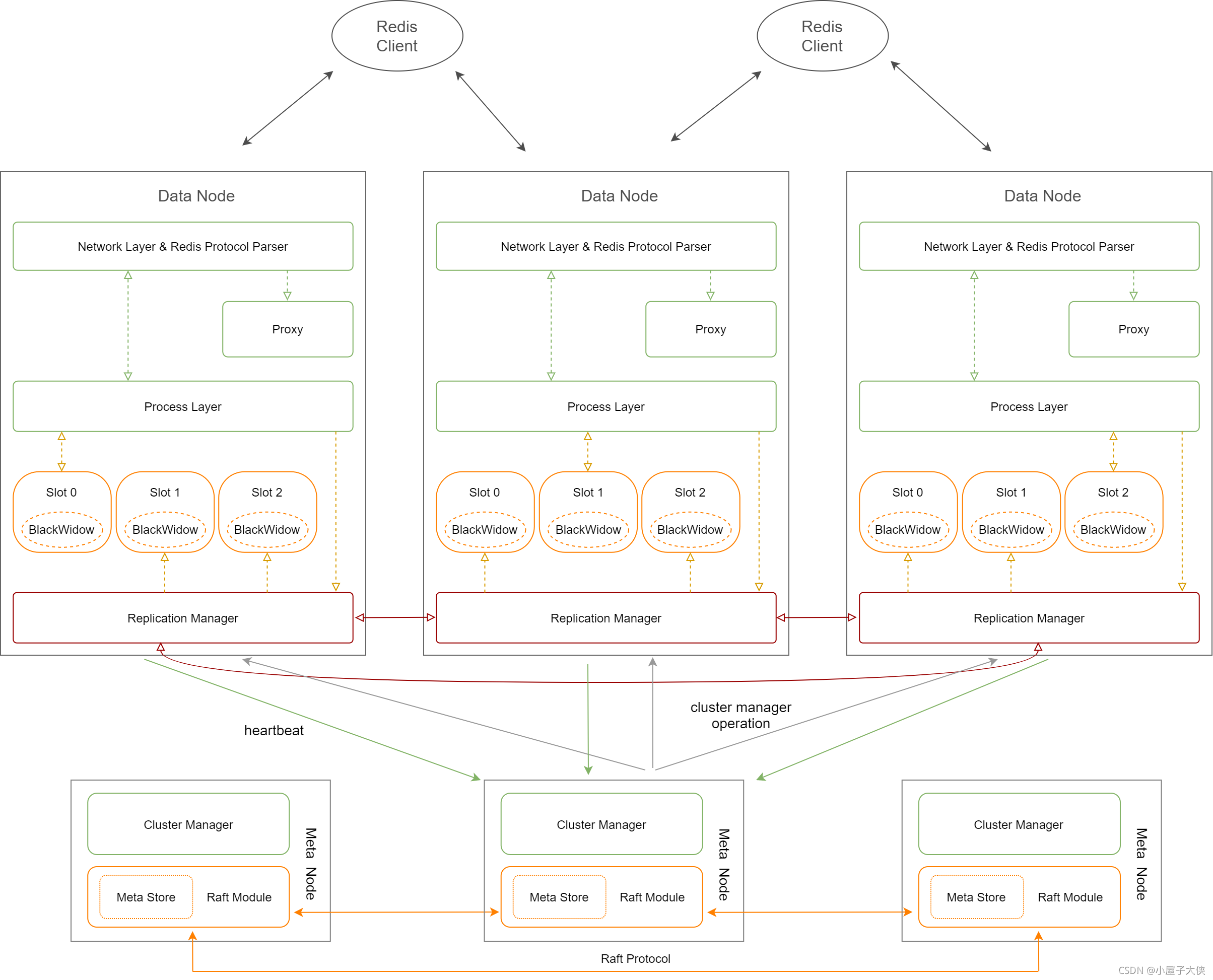
从原理图中,也可以清晰的看出经典模式以实例为维度,分布式模式以 slot 为维度。
pika 启动流程
基于 pika-3.4.0 版本的代码结构,其中 pika 引用了四个第三方的库,分别如下:
- Blackwidow,由 piak 自行维护的基于 rocksdb 的存储管理,所有 pika 的数据操作都会通过 blackwidow 的封装最终落入 rocksdb。
- Glog,日志库,用于 pika 项目输入不同等级的日志。
- Pink,由 pika 自行维护的事件驱动框架,封装了 redis 协议的解析分发功能,并提供回调函数进行处理。
- Slash,一些处理工具函数,例如同步的或者数据类型的工具函数。
启动流程中最主要的几个函数如下:
int main(int argc, char *argv[]) {
...
LOG(INFO) << "Server at: " << path;
g_pika_cmd_table_manager = new PikaCmdTableManager();
g_pika_server = new PikaServer();
g_pika_rm = new PikaReplicaManager();
g_pika_proxy = new PikaProxy();
if (g_pika_conf->daemonize()) {
close_std();
}
g_pika_proxy->Start();
g_pika_rm->Start();
g_pika_server->Start();
...
}
分为四步,即首先初始化 cmd 的命令,然后初始化 PikaServer,接着初始化 PikaReplicaManager,最后初始化 PikaProxy,主要的启动函数就是如上几步,接着就继续分析一下。
PikaServer 功能
PikaServer::PikaServer() :
exit_(false),
slot_state_(INFREE),
have_scheduled_crontask_(false),
last_check_compact_time_({0, 0}),
master_ip_(""),
master_port_(0),
repl_state_(PIKA_REPL_NO_CONNECT),
role_(PIKA_ROLE_SINGLE),
last_meta_sync_timestamp_(0),
first_meta_sync_(false),
loop_partition_state_machine_(false),
force_full_sync_(false),
slowlog_entry_id_(0) {
//Init server ip host
if (!ServerInit()) { // 初始化监听的端口和IP
LOG(FATAL) << "ServerInit iotcl error";
}
...
InitBlackwidowOptions(); // 初始化Blackwidow的参数项,主要配置rocksdb的相关参数
...
// Create thread 根据配置来查看有多少的工作线程数
worker_num_ = std::min(g_pika_conf->thread_num(),
PIKA_MAX_WORKER_THREAD_NUM);
std::set<std::string> ips;
if (g_pika_conf->network_interface().empty()) {
ips.insert("0.0.0.0");
} else {
ips.insert("127.0.0.1");
ips.insert(host_);
}
// We estimate the queue size 获取处理的队列的大小
int worker_queue_limit = g_pika_conf->maxclients() / worker_num_ + 100;
LOG(INFO) << "Worker queue limit is " << worker_queue_limit;
pika_dispatch_thread_ = new PikaDispatchThread(ips, port_, worker_num_, 3000,
worker_queue_limit, g_pika_conf->max_conn_rbuf_size()); // 设置处理响应请求的线程池
pika_monitor_thread_ = new PikaMonitorThread(); // 监控的线程池
pika_rsync_service_ = new PikaRsyncService(g_pika_conf->db_sync_path(),
g_pika_conf->port() + kPortShiftRSync); // 同步的线程池
pika_pubsub_thread_ = new pink::PubSubThread(); // 订阅发布处理线程
pika_auxiliary_thread_ = new PikaAuxiliaryThread(); // 心跳辅助的状态改变处理线程
pika_client_processor_ = new PikaClientProcessor(g_pika_conf->thread_pool_size(), 100000); // 处理异步的task
pthread_rwlock_init(&state_protector_, NULL);
pthread_rwlock_init(&slowlog_protector_, NULL);
}
这其中初始化了大量的工作线程,来启动协同处理分别启动了 6 个不同的线程池或者线程来进行不同的处理工作。
PikaDispatchThread
PikaDispatchThread::PikaDispatchThread(std::set<std::string> &ips, int port, int work_num,
int cron_interval, int queue_limit, int max_conn_rbuf_size)
: conn_factory_(max_conn_rbuf_size),
handles_(this) {
thread_rep_ = pink::NewDispatchThread(ips, port, work_num, &conn_factory_,
cron_interval, queue_limit, &handles_);
thread_rep_->set_thread_name("Dispatcher");
}
...
private:
class ClientConnFactory : public pink::ConnFactory {
public:
explicit ClientConnFactory(int max_conn_rbuf_size)
: max_conn_rbuf_size_(max_conn_rbuf_size) {
}
virtual std::shared_ptr<pink::PinkConn> NewPinkConn(
int connfd,
const std::string &ip_port,
pink::Thread* server_thread,
void* worker_specific_data,
pink::PinkEpoll* pink_epoll) const {
return std::static_pointer_cast<pink::PinkConn>
(std::make_shared<PikaClientConn>(connfd, ip_port, server_thread, pink_epoll, pink::HandleType::kAsynchronous, max_conn_rbuf_size_));
}
private:
int max_conn_rbuf_size_;
...
...
extern ServerThread *NewDispatchThread(
const std::set<std::string>& ips, int port,
int work_num, ConnFactory* conn_factory,
int cron_interval, int queue_limit,
const ServerHandle* handle) {
return new DispatchThread(ips, port, work_num, conn_factory,
cron_interval, queue_limit, handle);
...
...
DispatchThread::DispatchThread(const std::set<std::string>& ips, int port,
int work_num, ConnFactory* conn_factory,
int cron_interval, int queue_limit,
const ServerHandle* handle)
: ServerThread::ServerThread(ips, port, cron_interval, handle),
last_thread_(0),
work_num_(work_num),
queue_limit_(queue_limit) {
worker_thread_ = new WorkerThread*[work_num_];
for (int i = 0; i < work_num_; i++) {
worker_thread_[i] = new WorkerThread(conn_factory, this, queue_limit, cron_interval); // 生成多个工作线程,工作线程进来的请求通过conn_factory来进行处理
}
}
DispatchThread::~DispatchThread() {
for (int i = 0; i < work_num_; i++) {
delete worker_thread_[i];
}
delete[] worker_thread_;
}
int DispatchThread::StartThread() {
for (int i = 0; i < work_num_; i++) { // 根据设置的工作线程的数量来进行处理
int ret = handle_->CreateWorkerSpecificData(
&(worker_thread_[i]->private_data_));
if (ret != 0) {
return ret;
}
if (!thread_name().empty()) {
worker_thread_[i]->set_thread_name("WorkerThread");
}
ret = worker_thread_[i]->StartThread(); // 开启每一个工作线程
if (ret != 0) {
return ret;
}
}
return ServerThread::StartThread();
}
...
此时会使用 PikaDispatchThread 的工厂方法来处理新接入的连接,并且每一个新进来的请求通过 NewPinkConn 来进行初始化,并接入处理。其中 DispatchThread 就是位于 pink 的库中实现的方法其中 ServerThread 机会在初始化的过程中进行端口 IP 的监听,在事件响应之后就会调用 HandleNewConn 方法来处理新加入的连接信息,会在处理的过程中进行一个轮训的操作来分配到工作线程,在加入事件之后就会通过新生成一个 PikaClientConn 来进行事件处理,当 pink 中的 redisconn 解析到了完整的命令的时候就会调用 PikaClientConn 的 ProcessRedisCmds 方法来处理(中间的逻辑有点复杂大家有兴趣可以自��行查找源码阅读一下)。
void PikaClientConn::ProcessRedisCmds(const std::vector<pink::RedisCmdArgsType>& argvs, bool async, std::string* response) {
if (async) { // 是否是后台任务
BgTaskArg* arg = new BgTaskArg(); // 新建一个后台任务
arg->redis_cmds = argvs;
arg->conn_ptr = std::dynamic_pointer_cast<PikaClientConn>(shared_from_this());
g_pika_server->ScheduleClientPool(&DoBackgroundTask, arg); // 放入PikaClientProcessor的线程池来进行处理
return;
}
BatchExecRedisCmd(argvs); // 如果不是则调用响应的线程池直接处理
}
...
void PikaClientConn::BatchExecRedisCmd(const std::vector<pink::RedisCmdArgsType>& argvs) {
resp_num.store(argvs.size());
for (size_t i = 0; i < argvs.size(); ++i) { // 根据解析的输入参数大小来处理
std::shared_ptr<std::string> resp_ptr = std::make_shared<std::string>();
resp_array.push_back(resp_ptr);
ExecRedisCmd(argvs[i], resp_ptr); // 处理对应的命令
}
TryWriteResp();
}
...
void PikaClientConn::ExecRedisCmd(const PikaCmdArgsType& argv, std::shared_ptr<std::string> resp_ptr) {
// get opt
std::string opt = argv[0];
slash::StringToLower(opt);
if (opt == kClusterPrefix) { // 检查是否是集群名称开头
if (argv.size() >= 2 ) {
opt += argv[1];
slash::StringToLower(opt);
}
}
std::shared_ptr<Cmd> cmd_ptr = DoCmd(argv, opt, resp_ptr); // 执行命令
// level == 0 or (cmd error) or (is_read)
if (g_pika_conf->consensus_level() == 0 || !cmd_ptr->res().ok() || !cmd_ptr->is_write()) {
*resp_ptr = std::move(cmd_ptr->res().message());
resp_num--;
}
}
...
std::shared_ptr<Cmd> PikaClientConn::DoCmd(
const PikaCmdArgsType& argv,
const std::string& opt,
std::shared_ptr<std::string> resp_ptr) {
// Get command info
std::shared_ptr<Cmd> c_ptr = g_pika_cmd_table_manager->GetCmd(opt); // 从命令列表中查找命令
if (!c_ptr) {
std::shared_ptr<Cmd> tmp_ptr = std::make_shared<DummyCmd>(DummyCmd());
tmp_ptr->res().SetRes(CmdRes::kErrOther,
"unknown or unsupported command \'" + opt + "\"");
return tmp_ptr;
}
c_ptr->SetConn(std::dynamic_pointer_cast<PikaClientConn>(shared_from_this()));
c_ptr->SetResp(resp_ptr);
// Check authed
// AuthCmd will set stat_
if (!auth_stat_.IsAuthed(c_ptr)) { // 检查是否认证
c_ptr->res().SetRes(CmdRes::kErrOther, "NOAUTH Authentication required.");
return c_ptr;
}
uint64_t start_us = 0;
if (g_pika_conf->slowlog_slower_than() >= 0) {
start_us = slash::NowMicros();
}
bool is_monitoring = g_pika_server->HasMonitorClients(); // 是否是监控的客户端
if (is_monitoring) {
ProcessMonitor(argv);
}
// Initial
c_ptr->Initial(argv, current_table_); // 初始化命令信息
if (!c_ptr->res().ok()) {
return c_ptr;
}
g_pika_server->UpdateQueryNumAndExecCountTable(current_table_, opt, c_ptr->is_write());
// PubSub connection
// (P)SubscribeCmd will set is_pubsub_
if (this->IsPubSub()) {
if (opt != kCmdNameSubscribe &&
opt != kCmdNameUnSubscribe &&
opt != kCmdNamePing &&
opt != kCmdNamePSubscribe &&
opt != kCmdNamePUnSubscribe) {
c_ptr->res().SetRes(CmdRes::kErrOther,
"only (P)SUBSCRIBE / (P)UNSUBSCRIBE / PING / QUIT allowed in this context");
return c_ptr;
}
}
if (g_pika_conf->consensus_level() != 0 && c_ptr->is_write()) {
c_ptr->SetStage(Cmd::kBinlogStage);
}
if (!g_pika_server->IsCommandSupport(opt)) {
c_ptr->res().SetRes(CmdRes::kErrOther,
"This command is not supported in current configuration");
return c_ptr;
}
if (!g_pika_server->IsTableExist(current_table_)) {
c_ptr->res().SetRes(CmdRes::kErrOther, "Table not found");
return c_ptr;
}
// TODO: Consider special commands, like flushall, flushdb?
if (c_ptr->is_write()) {
if (g_pika_server->IsTableBinlogIoError(current_table_)) {
c_ptr->res().SetRes(CmdRes::kErrOther, "Writing binlog failed, maybe no space left on device");
return c_ptr;
}
std::vector<std::string> cur_key = c_ptr->current_key();
if (cur_key.empty()) {
c_ptr->res().SetRes(CmdRes::kErrOther, "Internal ERROR");
return c_ptr;
}
if (g_pika_server->readonly(current_table_, cur_key.front())) {
c_ptr->res().SetRes(CmdRes::kErrOther, "Server in read-only");
return c_ptr;
}
if (!g_pika_server->ConsensusCheck(current_table_, cur_key.front())) {
c_ptr->res().SetRes(CmdRes::kErrOther, "Consensus level not match");
}
}
// Process Command 执行命令
c_ptr->Execute();
if (g_pika_conf->slowlog_slower_than() >= 0) {
ProcessSlowlog(argv, start_us);
}
if (g_pika_conf->consensus_level() != 0 && c_ptr->is_write()) {
c_ptr->SetStage(Cmd::kExecuteStage);
}
return c_ptr;
}
...
通过层层的调用关系最终调用到了 Cmd 类的 Do 方法,例如 SetCmd 的执行流程如下:
void SetCmd::Do(std::shared_ptr<Partition> partition) {
rocksdb::Status s;
int32_t res = 1;
switch (condition_) {
case SetCmd::kXX:
s = partition->db()->Setxx(key_, value_, &res, sec_); // 通过db来设置key相关的信息
break;
case SetCmd::kNX:
s = partition->db()->Setnx(key_, value_, &res, sec_);
break;
case SetCmd::kVX:
s = partition->db()->Setvx(key_, target_, value_, &success_, sec_);
break;
case SetCmd::kEXORPX:
s = partition->db()->Setex(key_, value_, sec_);
break;
default:
s = partition->db()->Set(key_, value_);
break;
}
if (s.ok() || s.IsNotFound()) {
if (condition_ == SetCmd::kVX) {
res_.AppendInteger(success_);
} else {
if (res == 1) {
res_.SetRes(CmdRes::kOk);
} else {
res_.AppendArrayLen(-1);;
}
}
} else {
res_.SetRes(CmdRes::kErrOther, s.ToString());
}
}
至此就是通过一个简单的 set 命令来进行的流程,当然中间省略了很多复杂的交互细节,并且跳过了 pink 库的一个处理流程,最终会回调在 pika 中的 ProcessRedisCmds 处理。
PikaClientProcessor
PikaClientProcessor::PikaClientProcessor(
size_t worker_num, size_t max_queue_size, const std::string& name_prefix) {
pool_ = new pink::ThreadPool(
worker_num, max_queue_size, name_prefix + "Pool"); // 生成一个线程池
for (size_t i = 0; i < worker_num; ++i) { // 根据设置的线程池数量来初始化
pink::BGThread* bg_thread = new pink::BGThread(max_queue_size); // 初始化bg工作线程
bg_threads_.push_back(bg_thread); // 保存每个线程
bg_thread->set_thread_name(name_prefix + "BgThread");
}
}
主要是生成线程池来进行后台运行。在上一节中分析的 task 就是交给了 pool_线程池来进行数据的处理。一些协调数据同步的工作就交给了 bg_threads 线程池处理。
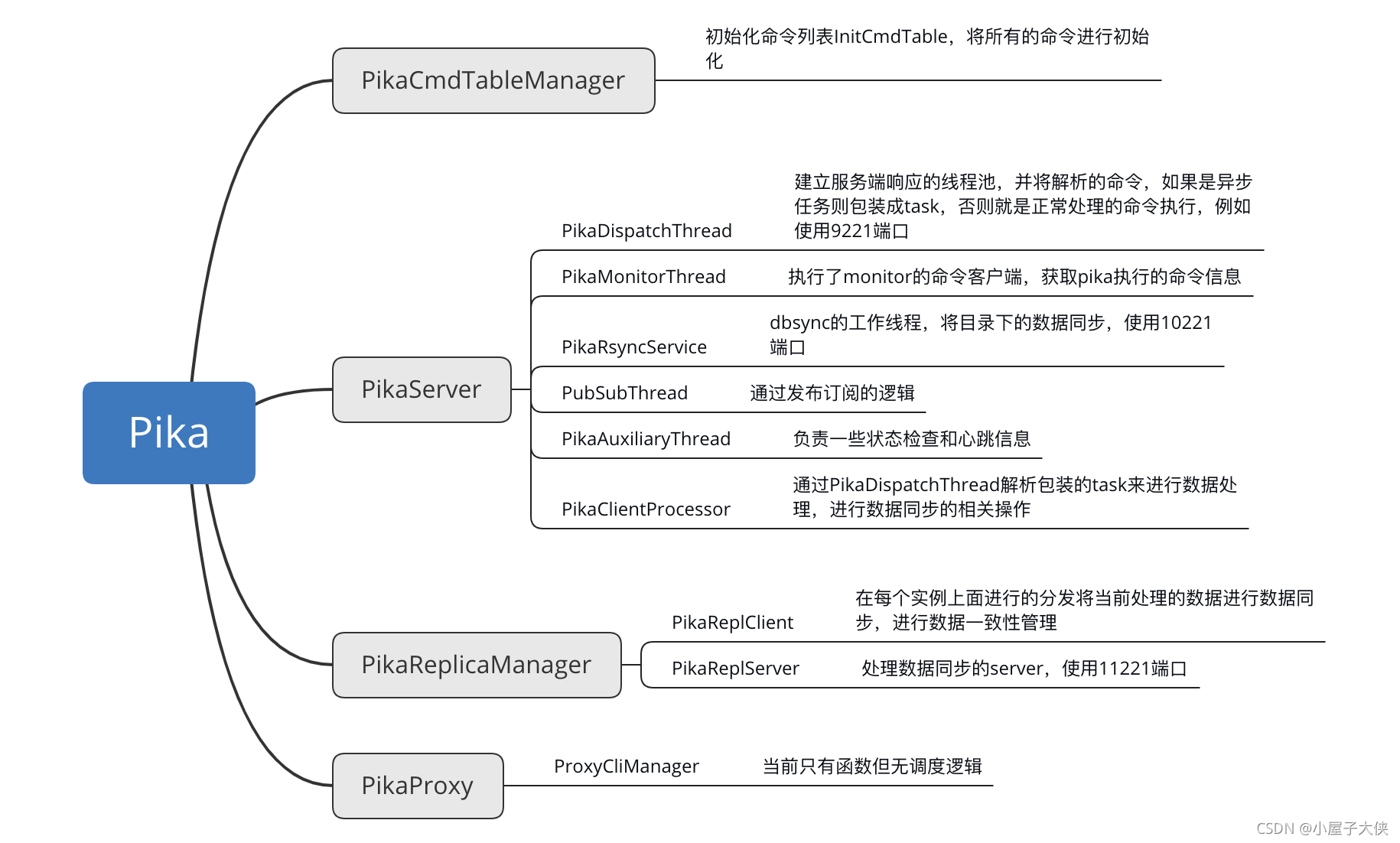
总结
本文主要简单的描述了有关 piak 的总体设计框架(参考官网架构),简单的通过 PikaServer 的启动过程来描述了一下基础的处理逻辑,因为这其中涉及到大量��的细节故并没有详尽的去分析,并且也没有涉及到其他的功能比如 slot 的数据一致性保证等等细节,后续有继续再继续查阅相关内容。由于本人才疏学浅,如有错误请批评指正。